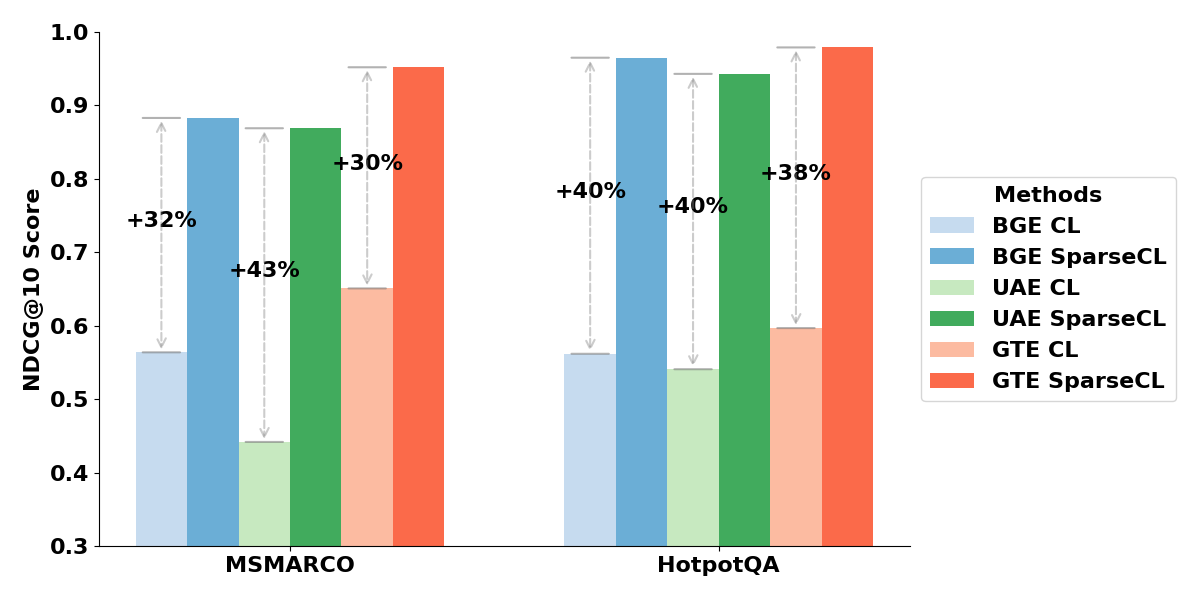
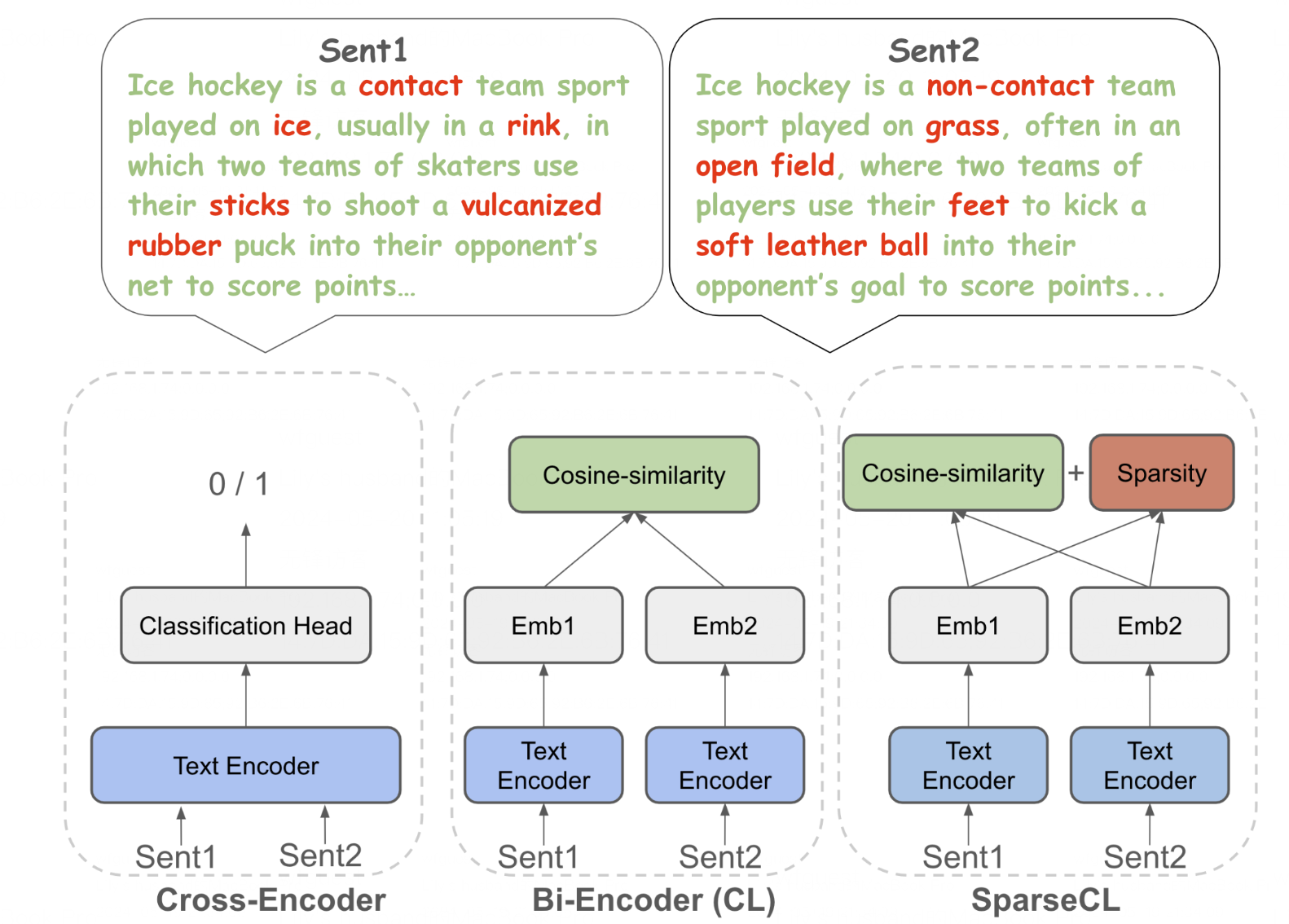
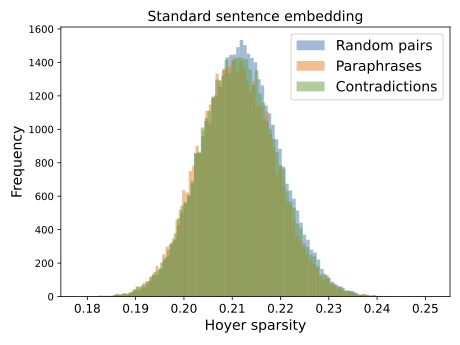
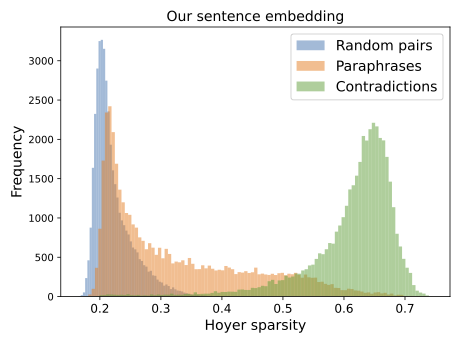
Reference
[1] Niall Hurley and Scott Rickard. Comparing measures of sparsity. IEEE Transactions on Information Theory, 55(10):4723–4741, 2009.
[2] Henning Wachsmuth, Shahbaz Syed, and Benno Stein. Retrieval of the best counterargument without prior topic knowledge. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 241–251, 2018.
[3] Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors, Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium, October-November 2018. Association for Computational Linguistics.
[4] Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. MS MARCO: A human generated machine reading comprehension dataset. CoRR, abs/1611.09268, 2016.
[5] Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-pack: Packaged resources
to advance general chinese embedding, 2023.
[6] Xianming Li and Jing Li. Angle-optimized text embeddings. arXiv preprint arXiv:2309.12871,
2023.
[7] Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang.
Towards general text embeddings with multi-stage contrastive learning. arXiv preprint
arXiv:2308.03281, 2023.
[8] Rui Meng, Ye Liu, Shafiq Rayhan Joty, Caiming Xiong, Yingbo Zhou, and Semih Yavuz.
Sfr-embedding-mistral:enhance text retrieval with transfer learning. Salesforce AI Research
Blog, 2024.